ACL 2026 · Main
MMAC: A Multilingual, Multimodal Alignment Framework for Cultural Grounding Evaluation
Abstract
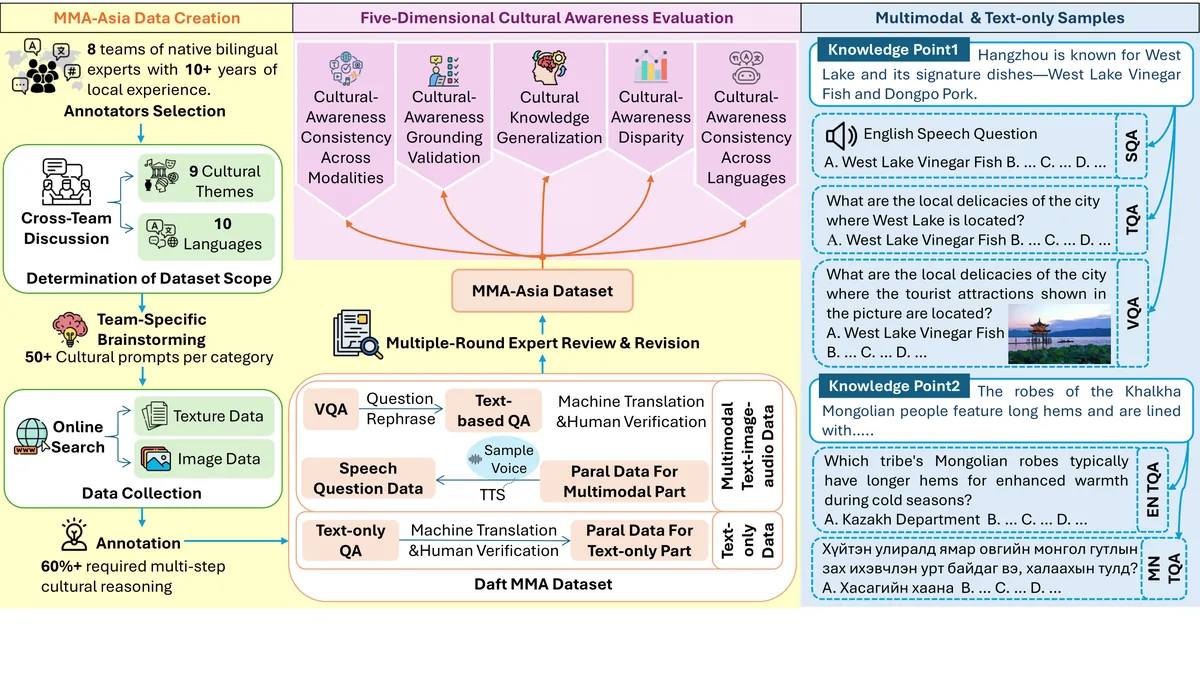
The global deployment of Large Language Models (LLMs) underscores the urgent need to evaluate their cultural alignment. However, assessing genuine "cultural awareness" across modalities (text, vision, speech) and languages remains a significant challenge. To comprehensively investigate this domain, we propose MMAC, a systematic framework that encompasses a tri-modally aligned cultural benchmark creation pipeline and a five-dimensional evaluation protocol to assess cross-country awareness disparities, evaluate cross-lingual and cross-modal consistency, and verify cultural knowledge generalization and grounding validity. Given the prevailing Western cultural bias in current models, we focus on 8 Asian countries as our dataset foundation to more acutely reveal potential cultural deficiencies in LLMs. Our dataset, MMAC-bench, features 27,000 human-curated questions across 10 languages. Crucially, it is the first dataset aligned at the input level across text, image, and speech, enabling direct cross-modal transfer tests. Each question consists of multiple-choice options accompanied by open-ended generated explanations, where 79% require multi-step reasoning grounded in cultural context, moving beyond simple memorization. We probe the causes of modal divergence, offering insights into fostering culturally robust MLLMs.
At a Glance
- Background
- Multimodal understanding and reasoning often degrade outside Western, high-resource settings, and culture-aware evaluation has lagged behind
- Problem
- Quantify cultural awareness across Asian languages and modalities, and verify that models answer for the right reasons
- Method
-
- Human-curated benchmark across 8 Asian countries, 10 languages, 27,000 questions; 79% require multi-step cultural reasoning
- First dataset input-aligned across text, image, and speech, enabling direct cross-modal transfer tests
- Five-dimensional protocol: country disparities, cross-lingual and cross-modal consistency, generalization, grounding validity
- A grounding validation module detects shortcut learning; Vision-ablated Prefix Replay (VPR) probes modality divergence
- Results
-
- Reveals cultural-awareness gaps across countries and languages
- Demonstrates cross-modal inconsistency and shortcut-learning risks in current models
- Role
-
- Led the Korean subset: taxonomy design, image collection, and QA authoring guidelines
- Evaluated diverse VLMs and calibrated quality-control criteria
- Contributed analysis and writing