ACL 2025 · Findings
Enhancing Automatic Term Extraction with Large Language Models via Syntactic Retrieval
Abstract
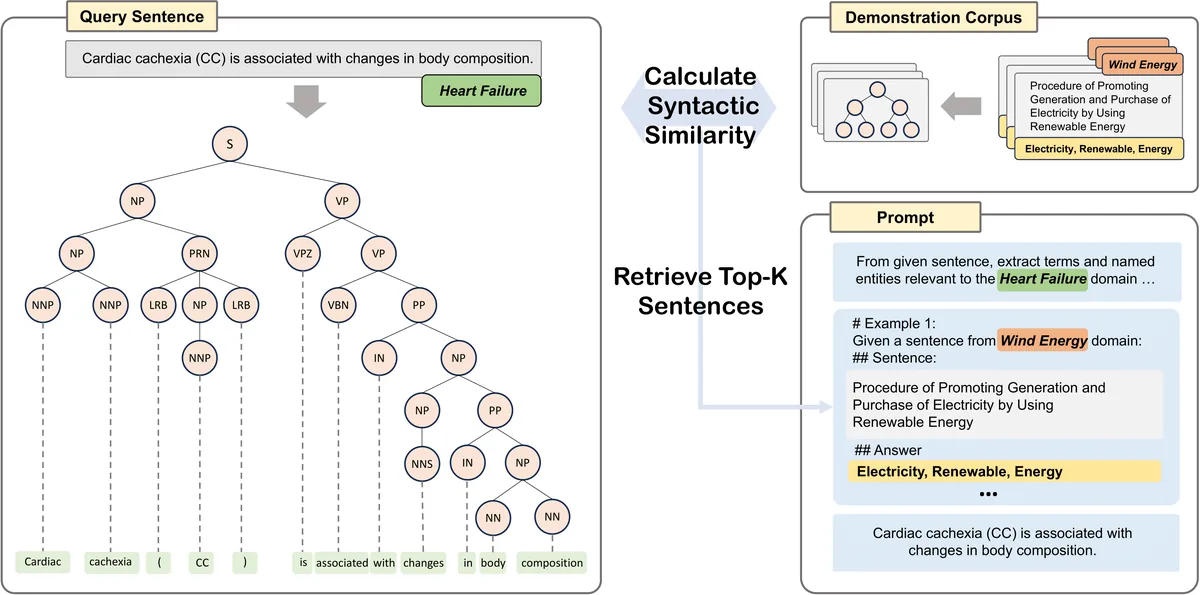
Automatic Term Extraction (ATE) identifies domain-specific expressions that are crucial for downstream tasks such as machine translation and information retrieval. Although large language models (LLMs) have significantly advanced various NLP tasks, their potential for ATE has scarcely been examined. We propose a retrieval-based prompting strategy that, in the few-shot setting, selects demonstrations according to syntactic rather than semantic similarity. This syntactic retrieval method is domain-agnostic and provides more reliable guidance for capturing term boundaries. We evaluate the approach in both in-domain and cross-domain settings, analyzing how lexical overlap between the query sentence and its retrieved examples affects performance. Experiments on three specialized ATE benchmarks show that syntactic retrieval improves F1-score. These findings highlight the importance of syntactic cues when adapting LLMs to terminology-extraction tasks.
At a Glance
- Background
-
- Automatic Term Extraction (ATE) identifies the domain-specific terms that underpin machine translation, information retrieval, and more
- LLM-based ATE is barely explored, and term-boundary identification is the hard part
- Problem
- Semantic-similarity demonstration retrieval misleads term-boundary recognition under domain mismatch, so retrieve demonstrations by syntax instead
- Method
-
- Retrieve few-shot demonstrations by syntactic similarity over parse trees using FastKASSIM
- Domain-agnostic guidance for capturing term boundaries
- Analyze how lexical overlap between the query and retrieved examples affects performance
- Results
-
- Consistent F1 gains on three specialized ATE benchmarks (ACTER, ACLR2, BCGM)
- Notably more stable than semantic retrieval in cross-domain settings
- Role
-
- Co-author: contributed to experiment design and methodology
- Supported the syntactic retrieval experiments and analysis