I’m a master’s student and researcher at Korea University advised
by
Dr. Heuiseok Lim. My work centers on AI Safety through
Mechanistic Interpretability and rigorous
Model Evaluation.
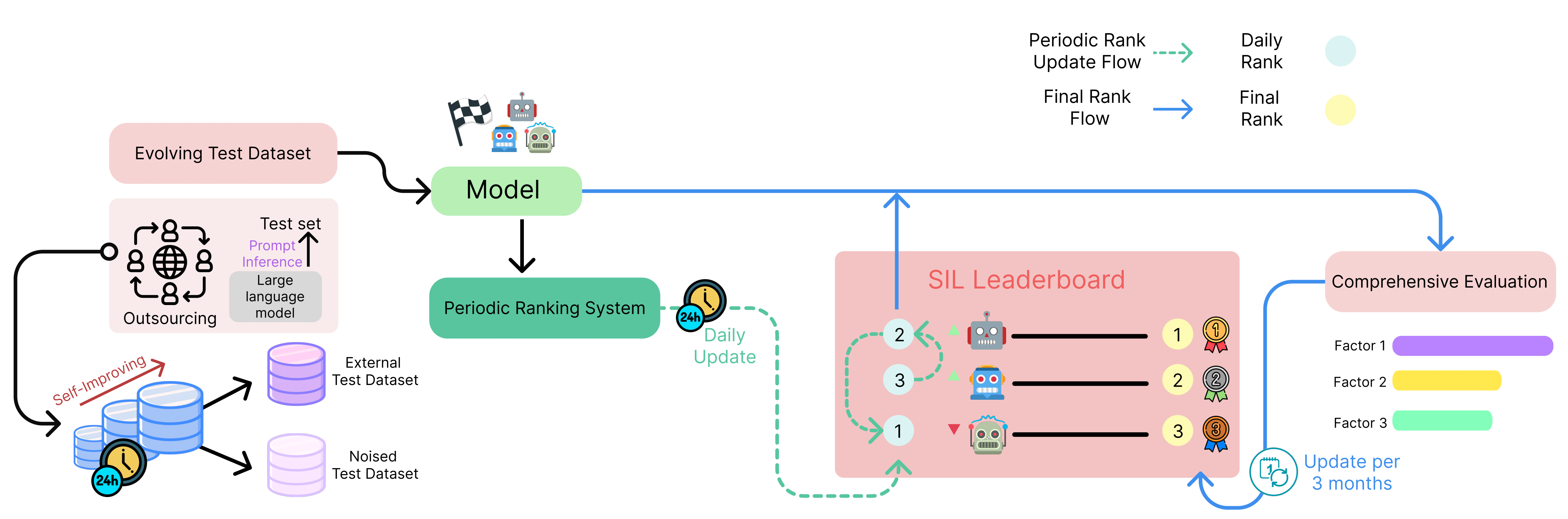
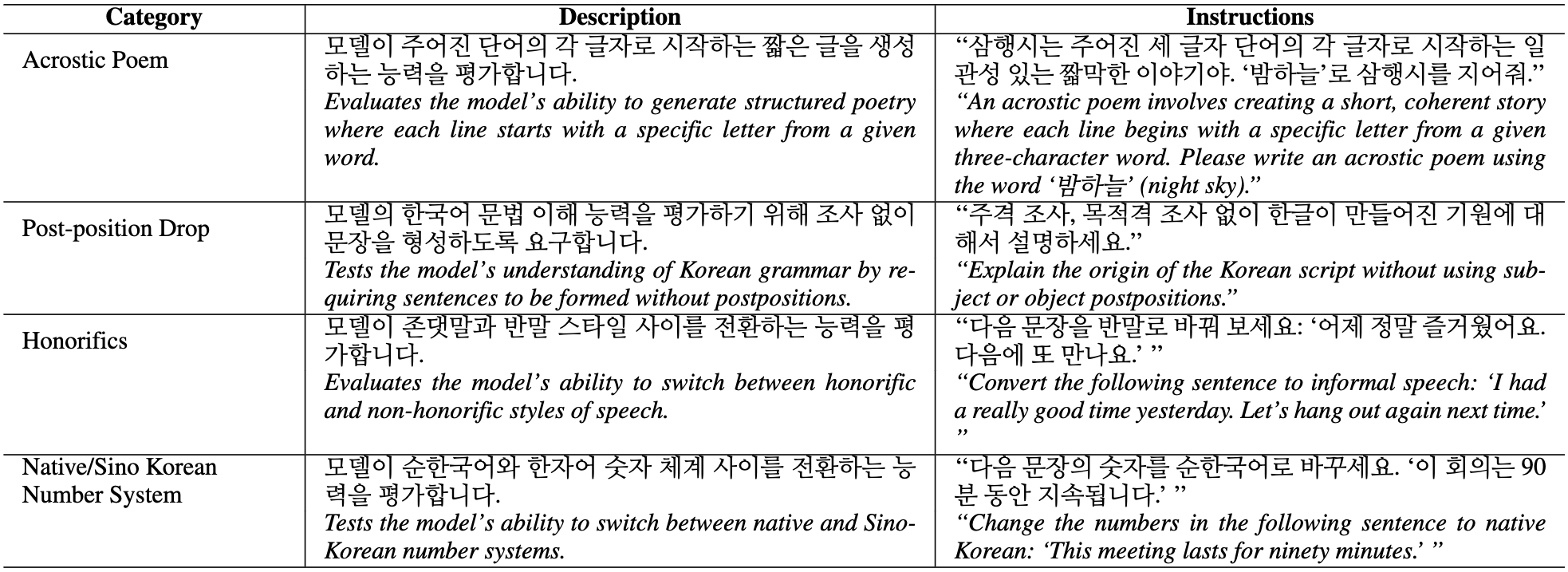
I design reproducible, time‑aware evaluation systems to measure
capabilities, surface failures, and track regressions; and I study
model internals to explain and steer behavior.
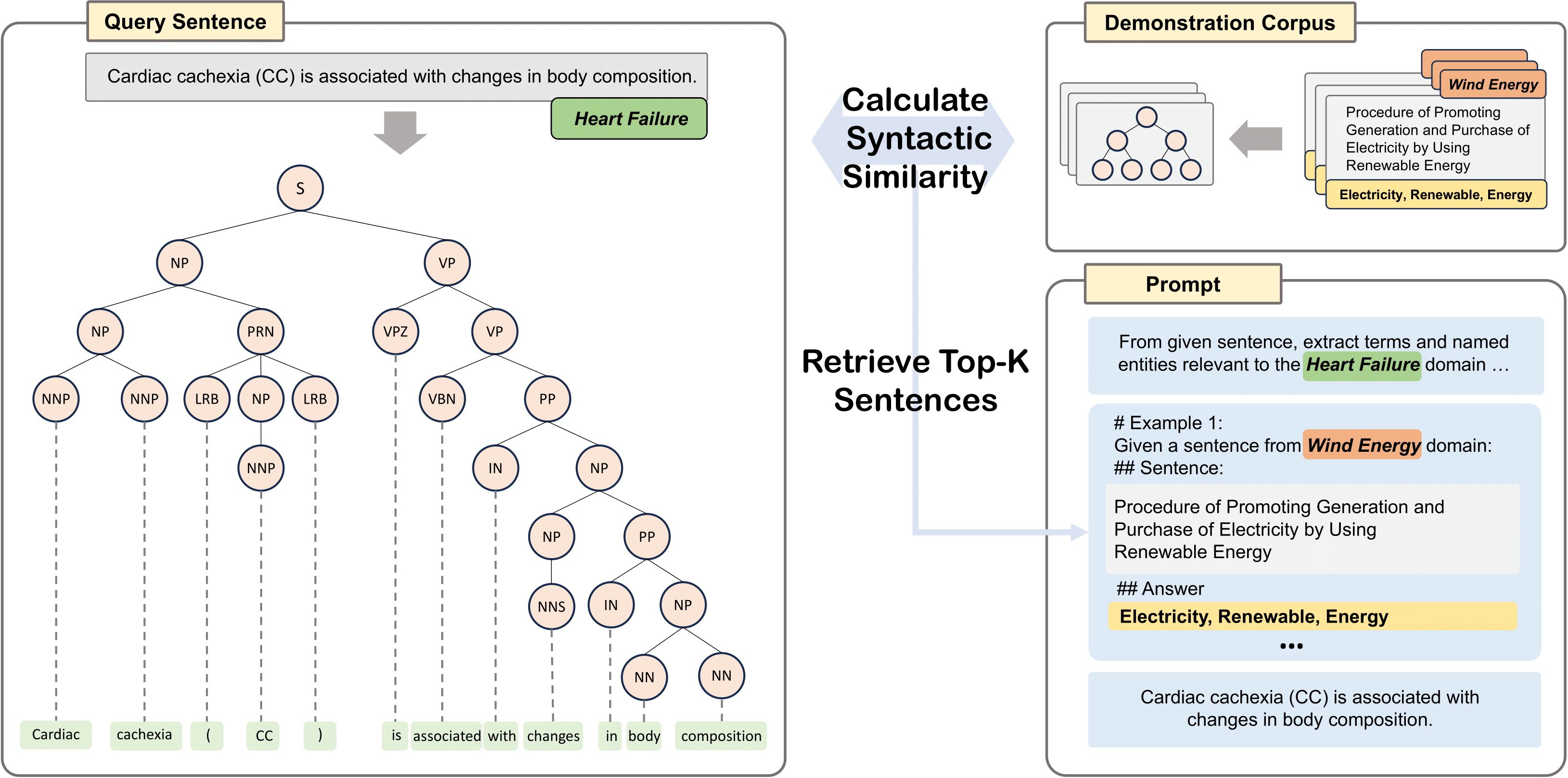
I’m experienced across the LLM training stack: dataset
curation/quality, instruction tuning and post‑training (including
RL with GRPO), and end‑to‑end evaluation and safety.
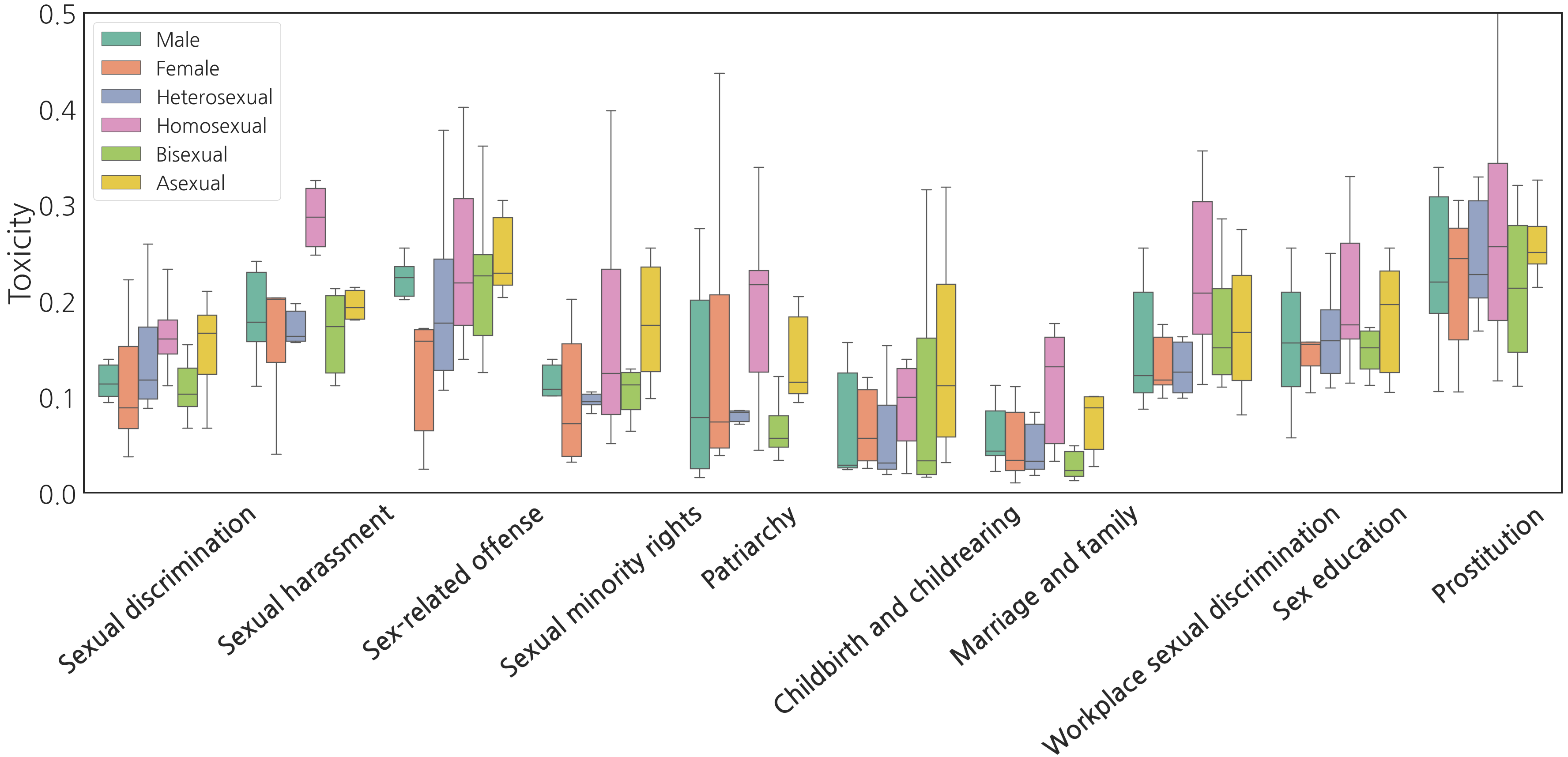
I work across evaluation, interpretability, safety, and reasoning.
Understanding how models work is key to unlocking capability and
reducing risk. If you’re exploring these areas, I’d love to
connect.